



李开复创办的AI公司零一万物(01.AI)近日陷入风波。
11月15日,创新工厂董事长兼CEO李开复在其微信朋友圈转发了旗下零一万物对于日前“套壳”争议的官方回应,并在配文中写道:“全球大模型架构一路从GPT2-->Gopher-->Chinchilla-->Llama2->Yi,行业逐渐形成大模型的通用标准(就像做一个手机APP开发者,不会去自创iOS、Android 以外的全新基础架构)。01.AI起步受益于开源,也贡献开源,从社区中虚心学习,我们会持续进步。”
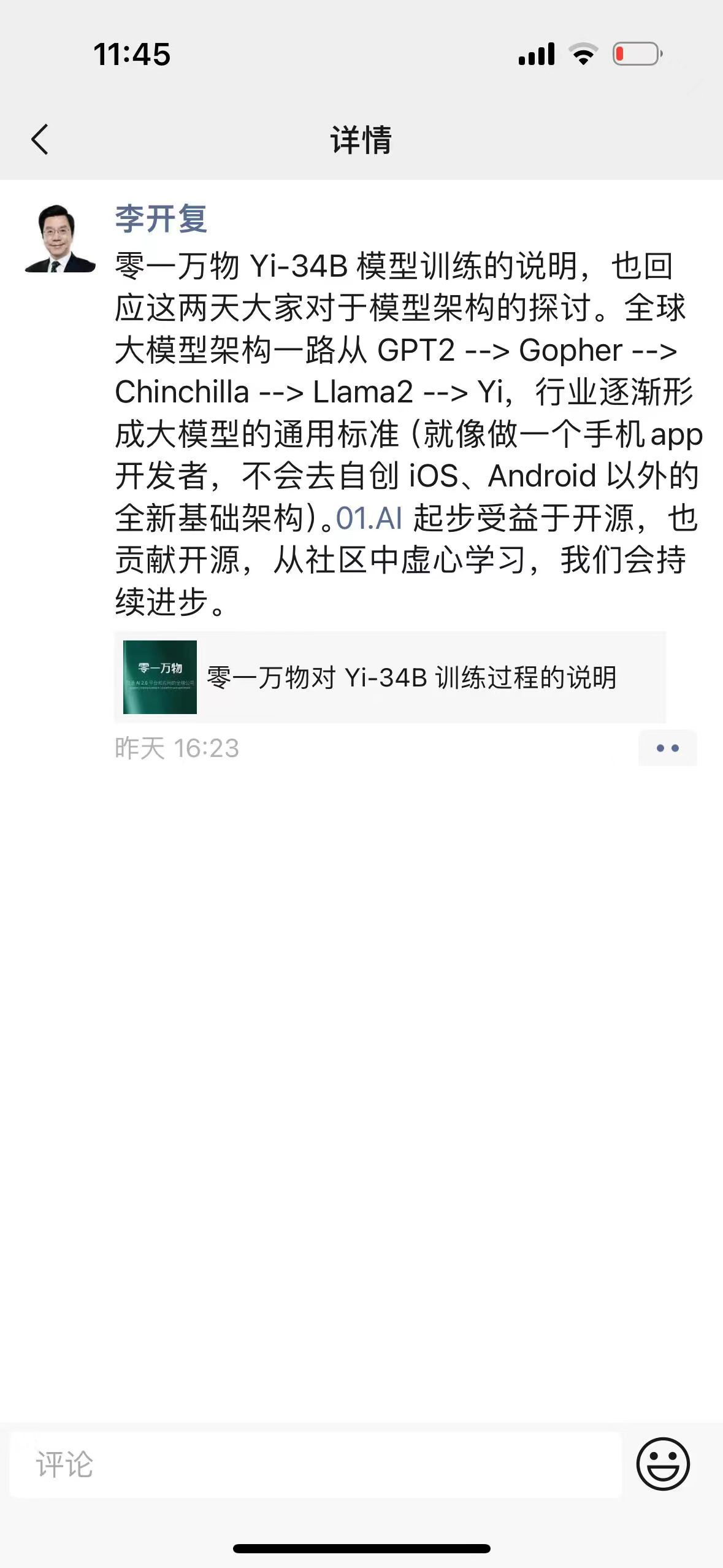
李开复朋友圈回应截图。来源:网络
在零一万物发布官方回应后,又有一张疑似原阿里技术副总裁贾扬清的朋友圈截图传出,强调在开源领域“魔改”不得:“开源是一个相互合作的事情,本质是要大家能够求同尊异,讨论设计,磨合观点,最后拧成一股绳往前走。”
这场风波起源于9天前,一位名为ehartford的国外开发者在英文开源社区Hugging Face上的零一万物开源主页上评论称,零一万物刚于上周完成了首秀的开源大模型Yi-34B完全使用了Meta研发的LLaMA的开源模型架构,只对其中的两个张量(Tensor)名称进行了修改,并且在模型中没有提及LLaMA,建议公司对这些问题进行改正后重新提交模型,以便于开发者将其与LLaMA直接对接。
而从11月14日起,一张微信朋友圈截图在国内大模型圈内广泛传播。在截图中,用户的备注名为原阿里首席AI科学家贾扬清,称有“某国内大厂的新模型”完全使用了Meta的开源大模型LLaMA的架构,只把代码中的大模型名字进行了修改并替换了几个变量名,并且“海外有工程师”指出了这点。
尽管零一万物从严格意义上来说并非“大厂”而是初创公司,由于时间和内容的重合度较高,许多大模型从业者将两件事情联系在一起,引发行业热议。有网友表示,在大模型领域使用开源产品并没任何问题,甚至有助于开源技术的发展,然而修改代码名称便不免会让人产生怀疑。
11月15日下午,零一万物(01.AI)回应了日前对其大模型Yi套用开源大模型LLaMA架构的质疑,表示大模型的核心不在于架构,而是在于训练得到的参数,以及代码名称问题属于“经实验更名后的疏忽”。
零一万物官方回应中表示,大模型社区在技术架构方面正处在接近于往通用化逐步收拢的阶段,国内已发布的开源模型绝大多数都采用渐成行业标准的GPT/LLaMA的架构,大模型“持续发展与寻求突破口的核心点”其实在于训练得到的参数。
零一万物强调,团队在训练前的实验中尝试了不同的数据配比,选取了最优的数据配比方案,进行了一系列“超越模型架构之外、研究与工程并进且具有前沿突破性的研发任务”。在模型训练的同时,零一万物也针对模型结构中的若干关键节点进行了大量的实验和对比验证,并在这个过程中对部分推理参数进行了重新命名。
在回应中,零一万物也对“沿用LLaMA部分推理代码经实验更名后的疏忽”表达了歉意:“(我们的)原始出发点是为了充分测试模型,并非刻意隐瞒来源。零一万物对此提出说明,并表达诚挚的歉意,我们正在各开源平台重新提交模型及代码并补充 LLaMA 协议副本的流程中, 承诺尽速完成各开源社区的版本更新。”
零一万物方面对澎湃新闻记者表示,此回应不针对网传的贾扬清朋友圈截图。
当天,在Hugging Face社区中,零一万物也对此事做了公开回应,表示感谢社区的指正,会重新提交模型。在零一万物做出回应后,开发者ehartford在评论中表示感谢。
一周前,11月6日,零一万物刚刚正式发布首款开源中英双语大模型Yi-34B,其拥有200K上下文窗口,可处理约40万字的文本。模型开放商用申请,在阿里云魔搭社区首发。与此同时,零一万物已完成新一轮融资,由阿里云领投。
据零一万物介绍,截至11月5日,Yi-34B在关键指标上胜过市场上已有的领先开源模型,包括大语言模型LLaMA 2,在Hugging Face英文开源社区平台的最佳性能大语言模型排行榜和C-Eval中文评测的最新榜单都爬升到第一位。目前,零一万物估值超过10亿美元。按此估值,堪称创业公司中的“独角兽”。

免责声明:中国网财经转载此文目的在于传递更多信息,不代表本网的观点和立场。文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。

















中国网是国务院新闻办公室领导,中国外文出版发行事业局管理的国家重点新闻网站。本网通过10个语种11个文版,24小时对外发布信息,是中国进行国际传播、信息交流的重要窗口。
凡本网站注明“来源:中国网财经”的所有作品,均为本网合法拥有版权或有权使用的作品,未经本网授权不得转载、摘编或利用其它方式使用上述作品。
电话:0086-10-82081166
传真:0086-10-82081900
邮箱:finance@china.org.cn
中国财经APP

官方微信

中国互联网视听节目服务自律公约 | 网络110报警服务 | 12321垃圾信息举报中心 | 友情链接
版权所有 中国互联网新闻中心 电话: 86-10-88828000 互联网新闻信息服务许可证10120170004号
信息网络传播视听节目许可证:0105123
 京公网安备 11010802027341号 京ICP证 040089号-1
京公网安备 11010802027341号 京ICP证 040089号-1
关于我们 | 法律顾问:北京岳成律师事务所 | 外宣服务与广告服务 | 违法和不良信息举报电话:010-88828271 举报流程










